
When Cloudflare announced early this month that it was introducing a default setting to block AI crawlers from accessing website content without permission, it was a big deal.
Companies are now required to disclose to Cloudflare customers why they want to crawl their site. Using Cloudflare’s new AI auditing tool, website owners can then make informed decisions about which bots, if any, it will allow to scrape their data.
Also in development at Cloudflare is a feature dubbed “Pay Per Crawl” which will give site owners the ability to demand payment from companies seeking to scrape their site.
It’s all part of a planned multi-prong approach by Cloudflare to empower its customers to be able to decide which crawlers they want to do business with.
Cloudflare reports that around 30% of global web traffic comes from bots, with activity surpassing human internet traffic in some locations. This impacts on website load times, with additional bandwidth costs for website owners. Website Read The Docs reported an AI crawler last year downloading 73TB in zipped HTML files from their own site, costing them over $5,000.
The DoubleVerify Fraud Lab reported in January that monthly General Invalid Traffic (GIVT) volumes has reached over 2 billion ad requests in the final quarter of 2024. Web AI crawlers are responsible for the dramatic increase in GIVT. This can put at risk accurate campaign metrics. As DoubleVerify note, the Media Rating Council (MRC) ensures industry standards are in place, protecting advertisers from wasted ad spend. Left unchecked, GIVT can distort campaign metrics, inflate impression counts, and cause further discrepancies.
What is Cloudflare? How big an impact could this have?
Around 20% of websites around the world use Cloudflare’s services, so a default opt-out setting from AI crawlers is going to create massive disruption to the web scraping that has become commonplace to feed LLM’s.
Back in September of 2024, Cloudflare introduced an initiative to block AI crawlers, with a one-click opt-out option. Since then, over one million customers have activated the feature.
Empowering Cloudflare customers to make active decisions about the AI crawlers they do and don’t want accessing their sites is in line with the broader array of services offered by the company.
Cloudflare offers customers products that boost the security, performance, and reliability of websites and applications. It sits between users and websites, optimising traffic flow, protecting against attacks, and improving the overall online experience.
Cloudflare VP of Product Will Allen spoke to Mediaweek about the new initiative, as well as the responsibility taken on by Cloudflare to serve as a good actor while controlling so much of the data transferred online.
“20% of the internet gets routed through us,” Allen explained. “So basically when you are typing in a domain, one of the core things we offer is this notion of a sort of a reverse proxy. So your request to your particular website, so it’s… willsguitars.com or something, it’s routed through Cloudflare first, and then sort of gets sent on to your actual database and origin.
“And the reason that matters is we then help protect you from all sorts of bad things that happen on the internet, like a DDoS attack. If there are bad actors out there trying to take down your website and you’re a publisher or news organisation, they’re gonna send a lot of malicious traffic to you. And when we operate as that sort of reverse proxy, the ability to sort of sit in front of and route those requests for your website, we can help mitigate that.”

Cloudflare VP of Product Will Allen
The responsibility for 20% of Internet traffic demands that Cloudflare keep a steady hand on the ship. And part of that responsibility now means giving customers tools to safeguard their sites against AI crawlers.
“‘How do we help build a better internet?’ That’s part of our mission statement, part of our philosophy. I’ve been at a number of companies where you have mission statements and philosophies that are somewhat divorced from the reality of the company. I can tell you that it’s just like not the case here,” Allen said, drawing the link between the AI crawlers and Cloudflare’s overall mission statement.
“We do this in all sorts of different ways: through research that we put out to push out in the world, through open standards. We have a massive free customer base where we give away our products for free, and it’s incredibly important to us.
“One of the ways we take it seriously is to look at the decisions you make, whether that’s from a technical perspective, a product perspective, a business perspective, and anchor it back to that same core question and mission: how do we help build a better Internet?
“What we heard from customers across the globe and across industries and every possible area was that they were concerned and have been concerned for many, many years about bots and bot traffic. We’ve been fighting bots since we started. So, for 15 years, basically, we’ve been fighting bots.”
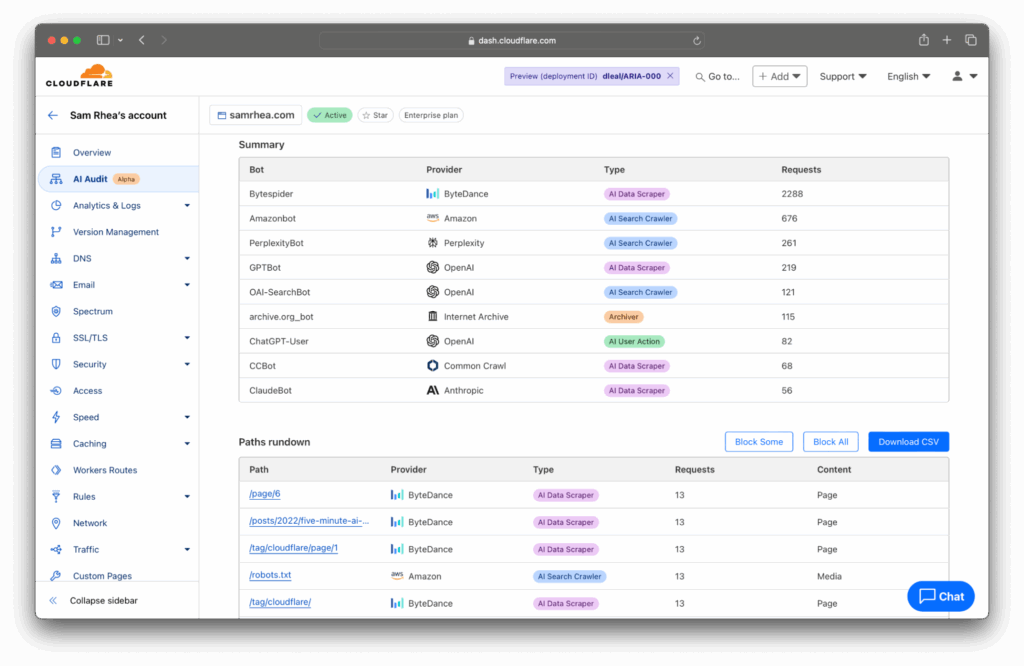
Cloudflare AI Audit
Support from publishers
AI crawler scraping has led to multiple lawsuits already, with many more on the horizon. Notably Disney and Universal have filed a suit against San Francisco-based AI company Midjourney, while a collective of authors including Sarah Silverman and Ta-Nehisi Coates last month lost a case against Meta, claiming had breached copyright law by using their books without permission to train its AI system.
Will Allen said that Cloudflare was looking to give content creators some semblance of control. In making the announcement to the public about Cloudflare’s new opt-out functionality, the company was joined in voice by multiple publishing heavyweights with positive comment for the move.
Roger Lynch, Chief Executive Officer of Condé Nast:
“Cloudflare’s innovative approach to block AI crawlers is a game-changer for publishers and sets a new standard for how content is respected online. When AI companies can no longer take anything they want for free, it opens the door to sustainable innovation built on permission and partnership. This is a critical step toward creating a fair value exchange on the Internet that protects creators, supports quality journalism and holds AI companies accountable.”
Vivek Shah, Chief Executive Officer of Ziff Davis:
“We applaud Cloudflare for advocating for a sustainable digital ecosystem that benefits all stakeholders — the consumers who rely on credible information, the publishers who invest in its creation, and the advertisers who support its dissemination.”
Renn Turiano, Chief Consumer and Product Officer at Gannett Media:
“As the largest publisher in the country, comprised of USA TODAY and over 200 local publications throughout the USA TODAY Network, blocking unauthorised scraping and the use of our original content without fair compensation is critically important. As our industry faces these challenges, we are optimistic the Cloudflare technology will help combat the theft of valuable IP.”
‘Opt-in’ is just the first step
Allen told Mediaweek that he was surprised at the interest shown in the measure from professionals across industries. Initial conversations internally and externally had focused more on news and publishing, but they found that interest was broader.
He explained that “if you’re an e-commerce site, if you’re a small retailer, you’re thinking a lot about the future of commerce and how people make purchasing decisions. If you’re in the healthcare space, you’re thinking about this. If you are, you know, an AI company yourself, you’re thinking about, hey, how do I go out and sort of not only ingest content, but how do I get the most interesting and relevant and important content that’s timely for what you’re doing? And then how do I stop other bad actors from taking what I’m doing?”
Cloudflare didn’t surprise the industry in taking the measure to block by default. Matthew Prince, co-founder and CEO of Cloudflare, has been vocal about the issue for some time. Internally, it has been about a year since the business began thinking about it and consulting customers.
Launching the opt-in function is just the first step in what Cloudflare has planned.
“We launched some of the first abilities to get to the first step to say: ‘okay, what’s going on? How do we get a granular view of the data?’ And then really just followed our customers, what they’re asking for… helping them understand more of what’s going on.”